
Contents
0%The difference between a mediocre AI output and one that actually converts comes down to how you write your prompt. That's not an opinion, it's something we see daily at Starpop, where thousands of users generate marketing videos, images, and audio through models like OpenAI Sora, Google Veo, and Kling. The users who get the best results aren't necessarily more creative. They just understand prompt structure. That's exactly why having a solid openai prompt engineering guide matters more now than ever.
OpenAI has published and updated its own prompting documentation, but it's scattered across technical docs and research papers. Most of it was written for developers building API integrations, not for marketers and creators trying to produce better ads or scale content. So we pulled together the most useful strategies, from OpenAI's official recommendations and from what we've tested internally, into a single, practical reference you can actually use.
This guide covers the core techniques: writing clear instructions, providing reference examples, breaking complex tasks into steps, and giving the model time to reason. Each section includes real prompt examples and explains why they work. Whether you're generating ad scripts, product visuals, or localized video content, these practices apply directly to the work you're already doing.
What prompt engineering means in 2026
Prompt engineering used to mean adding "please" or "be specific" to a text box and hoping for a useful response. In 2026, it means something much more deliberate. Modern AI models, including the ones covered in this openai prompt engineering guide, respond to structure, context, and specificity. You're not just typing a request; you're defining a contract with the model about what good output looks like.
The Shift From Requests to Instructions
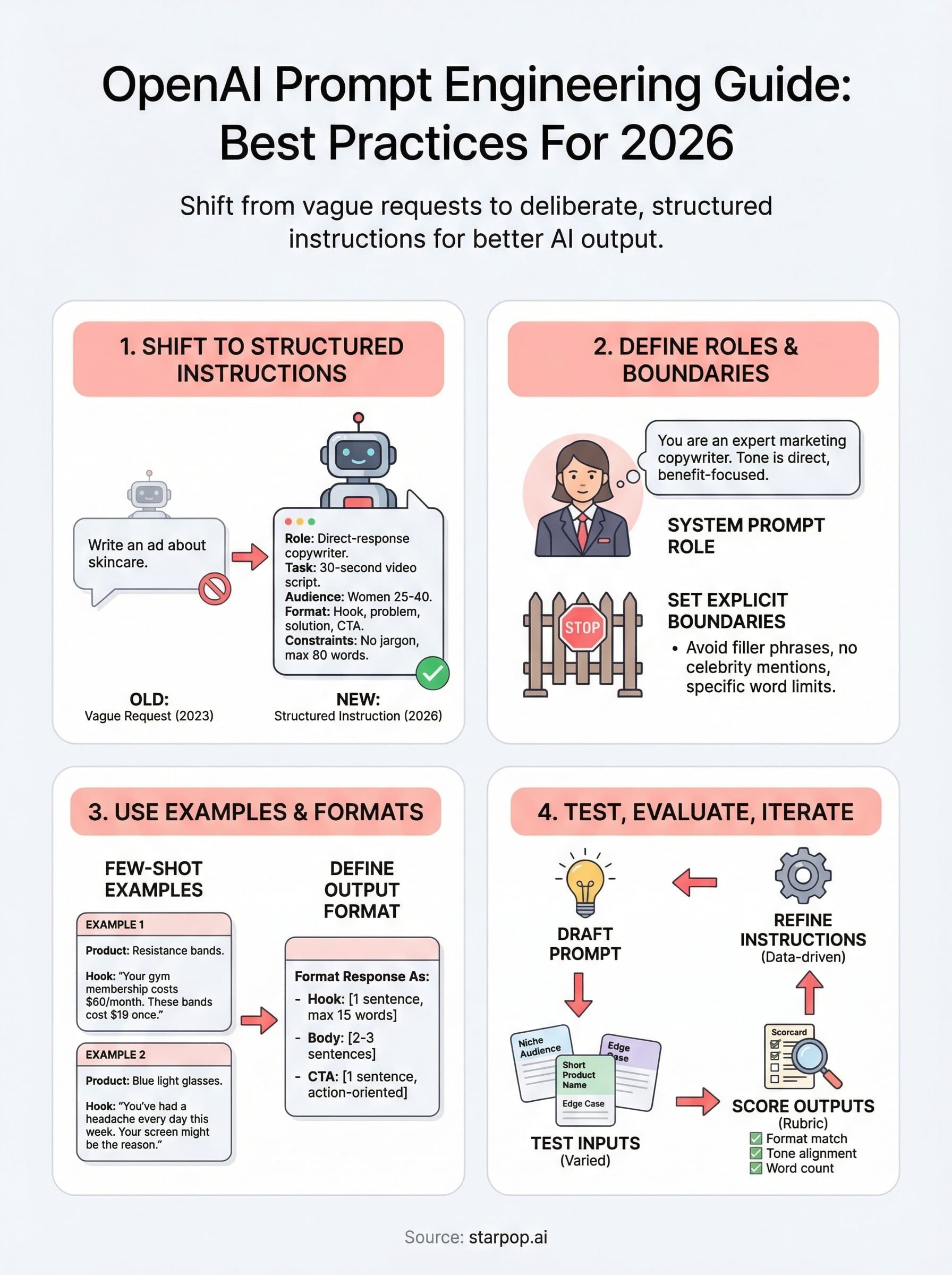
The biggest change in how models behave is that they now follow explicit, layered instructions far more reliably than they did two or three years ago. Models like GPT-4o and o3 are trained using reinforcement learning from human feedback, which means they've learned to respect constraints, maintain personas, and follow multi-step directions within a single prompt. That creates a direct opportunity for you: if you write your prompts like a clear instruction set, the model treats them that way.

The prompt is no longer a search query. It's closer to a job description, and the model is the hire.
What used to require multiple messages and back-and-forth iteration can now happen in a single, well-structured prompt. You define the role the model should play, the output format you expect, the boundaries it shouldn't cross, and any examples that illustrate your target result. The model reads all of that at once and uses it to shape every part of its response.
Why This Matters for Marketing and Creative Work
For marketers and content creators, this shift has direct practical value. When you're generating a batch of ad scripts, product descriptions, or video prompts, even small improvements in prompt quality compound quickly across dozens or hundreds of outputs. A prompt that specifies tone, audience, format, and constraints will consistently outperform one that only states the topic.
Here's a comparison of how a vague prompt and a structured prompt differ in practice:
| Element | Vague Prompt | Structured Prompt |
|---|---|---|
| Role | None | "You are a direct-response copywriter" |
| Task | "Write an ad" | "Write a 30-second UGC video script" |
| Audience | None | "For women 25-40 interested in skincare" |
| Format | None | "Hook, problem, solution, CTA" |
| Constraints | None | "No jargon, max 80 words, no celebrity mentions" |
What's Actually New in 2026
Two developments define prompt engineering today more than anything else. First, reasoning models like OpenAI's o3 benefit from prompts that give them space to work through a problem step by step, rather than demanding an instant final answer. Second, multimodal inputs now let you include images, audio clips, or video frames directly in your prompt context, which opens up entirely new use cases for production work.
Both of these changes mean that your prompts need to evolve alongside the models themselves. A strategy that worked well with GPT-3.5 will leave performance on the table when applied to current systems. Understanding how each model processes input, and writing prompts that align with that specific behavior, is what separates average outputs from ones you'd actually publish or run as paid ads.
Choose the right model and settings
Before you write a single word of your prompt, you need to pick the right model for the job. This is one of the most overlooked steps in any openai prompt engineering guide, and getting it wrong wastes both tokens and time. OpenAI's model lineup in 2026 covers a wide range of capabilities and cost points, and each model responds differently to the same prompt structure.
Match the Model to the Task
Not every task needs the most powerful model available. GPT-4o handles most creative and conversational tasks with low latency and strong instruction-following. o3 and o4-mini are reasoning models designed for complex, multi-step problems where accuracy matters more than speed. For high-volume tasks like batch-generating ad copy variations or product descriptions, a faster and cheaper model often gives you 90% of the quality at a fraction of the cost.
Choosing the wrong model is like hiring a surgeon to do a grocery run. Match capability to task complexity.
Use this reference to make faster decisions:
| Task Type | Recommended Model | Why |
|---|---|---|
| Ad scripts, product copy | GPT-4o | Fast, strong instruction-following |
| Multi-step reasoning, analysis | o3 | Designed for chain-of-thought tasks |
| High-volume batch generation | GPT-4o mini | Lower cost, sufficient quality |
| Code generation or debugging | o4-mini | Optimized for structured output |
| Image or video prompt creation | GPT-4o (multimodal) | Accepts visual input as context |
Tune the Key Parameters
Once you pick your model, temperature and max tokens are the two settings that most directly shape your output quality. Temperature controls how creative or predictable the response is. A value of 0.2 to 0.5 works well for structured marketing copy where consistency matters. A value of 0.8 to 1.0 suits brainstorming or generating varied creative concepts.
Set max tokens deliberately rather than leaving it at the default. If you need a 50-word hook, cap the output accordingly. Leaving it open invites the model to pad responses, which forces you to edit downstream. Keeping your parameter settings tight and intentional from the start reduces post-processing time and keeps your outputs closer to what you actually need.
Structure prompts with roles and boundaries
Every model in this openai prompt engineering guide responds better when you give it a defined role before the task starts. Without a role, the model defaults to a generic assistant voice, which rarely matches what you actually need. Assigning a role frames the entire response: tone, vocabulary, level of detail, and even how confidently the model states information all shift based on who you tell it to be.
Define the Role Upfront
You set the role in the system prompt, and it should be specific rather than generic. "You are a helpful assistant" gives the model almost nothing useful to work with. "You are a direct-response copywriter specializing in short-form video ads for e-commerce brands" gives it a clear persona to inhabit for every output it produces.
The more precisely you describe the role, the less the model has to guess, and guessing is where quality drops.
Here is a prompt structure template you can adapt for your own work:
System:
You are a [specific role] with expertise in [domain].
Your tone is [adjective], [adjective], and [adjective].
You write for [specific audience].
User:
[Your task here with format and constraints.]
For example: "You are a performance marketing copywriter with expertise in skincare e-commerce. Your tone is direct, conversational, and benefit-focused. You write for women aged 25-40 who scroll quickly past ads."
Set Boundaries That Stick
Boundaries define what the model should avoid or refuse, and they belong in the same system prompt as the role. Without explicit boundaries, the model will fill gaps with its own defaults, which often include filler phrases, hedging language, or tangents that waste your token budget.
Effective boundaries are concrete and specific. Instead of "keep it professional," write "avoid jargon, do not use phrases like 'dive into' or 'game-changer,' and never exceed 100 words per output." That level of specificity removes ambiguity and keeps every generation tight and on-target, which matters especially when you are running batch jobs across dozens of creative variations. The model treats boundaries as hard constraints when you phrase them as direct prohibitions rather than soft preferences.
Write instructions that models follow
The quality of your instructions determines the quality of your output. Every step in this openai prompt engineering guide depends on how clearly you communicate what you want. Models don't interpret implied meaning well; they follow literal directions, so vague instructions produce vague results. Writing sharp, direct instructions is the fastest way to close the gap between what you picture and what the model actually generates.
Use Positive, Direct Commands
Tell the model what to do rather than what to avoid. "Write a 60-word hook in the second person" is far stronger than "don't write too long and avoid third person." Positive commands give the model a clear target to aim at, while negative-only instructions leave too much open to interpretation. Verbs like "list," "summarize," "rewrite," and "generate" anchor your request and remove ambiguity from the start.
Instructions that tell a model what to produce always outperform instructions that only tell it what to skip.
Here's a direct comparison:
| Weak Instruction | Strong Instruction |
|---|---|
| "Make it short" | "Write exactly 3 sentences" |
| "Sound natural" | "Use contractions and first-person voice" |
| "Don't be boring" | "Open with a question or a surprising fact" |
Break Complex Tasks Into Steps
When your task has multiple components, numbered step lists inside the prompt perform better than a single dense paragraph of instructions. Models process sequential instructions more accurately because each step acts as a discrete checkpoint. If you need the model to analyze a product, then write three ad hooks, then suggest a CTA, lay those out as steps one, two, and three rather than collapsing everything into one run-on request.

Use this template for multi-step instructions:
Step 1: [First action]
Step 2: [Second action, based on Step 1 output]
Step 3: [Final action with format specification]
Format: [Describe the final output structure here]
Separating each instruction also makes iteration faster and more precise. If Step 2 produces weak output, you revise that step without rebuilding the entire prompt from scratch. That kind of modular structure cuts your testing time and keeps your prompt history clean when you're running batch jobs across multiple creative variations.
Add examples and structured outputs
Examples are the fastest way to close the gap between what you describe and what the model actually produces. Even the best-written instruction in any openai prompt engineering guide can leave room for interpretation. When you include one or two concrete examples directly in your prompt, the model treats them as a quality reference and calibrates every part of its output to match that standard.
Examples communicate your quality bar faster and more accurately than any written description alone.
Use Few-Shot Examples to Shape Output
Few-shot prompting means giving the model two to four sample inputs and outputs before asking it to handle your real task. You don't need dozens of examples; even two well-chosen ones shift output quality significantly. Place your examples in the user message using a clear label like "Example 1:" and "Example 2:" so the model can parse them as separate reference points and apply each one to your actual task.
Here's a template you can adapt:
System:
You are a direct-response copywriter for e-commerce brands.
User:
Here are two examples of strong product hooks.
Example 1:
Product: Resistance bands
Hook: "Your gym membership costs $60/month. These bands cost $19 once."
Example 2:
Product: Blue light glasses
Hook: "You've had a headache every day this week. Your screen might be the reason."
Now write a hook for this product:
Product: [Your product here]
The structure labels each example clearly, which keeps your prompt format consistent and makes outputs far easier to predict and reuse across batch jobs.
Define the Output Format Explicitly
Telling the model what structure you want prevents it from choosing its own format, which rarely matches what you need. Specifying format details like word count, heading labels, bullet count, or JSON field names gives you outputs that slot directly into your workflow without manual reformatting.
Use a format block at the end of your prompt to lock this in:
Format your response as:
- Hook: [1 sentence, max 15 words]
- Body: [2-3 sentences explaining the benefit]
- CTA: [1 sentence, action-oriented]
This removes formatting guesswork from every generation and keeps your batch outputs consistent across dozens of creative variations.
Ground answers with context and tools
Context is what separates a generic model response from one that feels like it was written specifically for your product, audience, and campaign. Every model covered in this openai prompt engineering guide performs better when you supply the background it needs upfront rather than waiting for it to ask follow-up questions. Think of context as the briefing document you'd hand to a new hire before asking them to write your first ad.
The model can only work with what you give it, so giving it more of the right information always produces sharper output.
Inject Relevant Context Directly
You can front-load your prompt with product details, brand guidelines, or audience data and the model will apply that information throughout every part of its response. This is especially useful when you generate multiple assets in a single session. Instead of repeating your brand voice instructions across separate prompts, you embed them once in the system message and every output inherits them automatically.
Here is a practical context block you can paste into any system prompt:
Context:
- Brand: [Brand name]
- Product: [Product name and core benefit]
- Target audience: [Age range, key interest, main pain point]
- Tone: [2-3 adjectives]
- Hard rules: [Any non-negotiable copy restrictions]
Fill each field with specific, concrete details rather than broad descriptors, and every generation you run in that session will reflect your actual brand rather than a generic approximation of it.
Use Tool Calls to Extend Model Capability
When your prompt requires real-time data, external lookups, or structured database queries, native model knowledge runs out quickly. OpenAI's function-calling feature lets you connect the model to live tools, like a product catalog API or a performance data feed, so its responses are grounded in current, accurate information rather than training data that may be months old.
For marketing teams, this means you can pipe in live ad performance metrics and ask the model to generate new scripts based on what's actually converting. You stop guessing and start building prompts that respond directly to real campaign signals.
Test, evaluate, and iterate safely
Writing a strong prompt is only half the work in any practical openai prompt engineering guide. The other half is running it against real inputs, measuring whether the outputs hit your target quality bar, and refining based on what the data actually shows rather than gut feel. Skipping this step means you're shipping prompts you haven't validated, which leads to inconsistent outputs at scale.
Build a Prompt Testing Workflow
You need a repeatable process to test prompts before you push them into production or batch jobs. The simplest approach is to run each prompt against five to ten varied inputs that cover your expected range of use cases. Include edge cases, like short product names, niche audiences, or unconventional requests, because those are the inputs that expose weak spots in your instruction structure.

A prompt that works on your best example but breaks on your second-best is not a production-ready prompt.
Use this workflow for every prompt you write:
1. Draft the prompt with role, instructions, and format block.
2. Run it against 5 test inputs covering easy, mid, and edge cases.
3. Record each output and flag any that miss the format, tone, or word count.
4. Identify the single most common failure point.
5. Revise that specific instruction and retest before changing anything else.
Changing one variable at a time keeps your iteration clean and tells you exactly which edit produced the improvement.
Score Outputs Against a Fixed Rubric
Without a scoring rubric, your evaluation is subjective and inconsistent across sessions. Build a simple rubric with three to five criteria and score each output on a 1 to 3 scale before deciding whether to revise. That gives you a comparable baseline across every prompt version you test.
A basic rubric for marketing copy outputs looks like this:
| Criterion | 1 (Fail) | 2 (Acceptable) | 3 (Strong) |
|---|---|---|---|
| Format match | Wrong structure | Mostly correct | Exact match |
| Tone alignment | Off-brand | Close | On-brand |
| Word count | Over or under by 30%+ | Within 15% | Within 5% |
| Instruction compliance | Multiple misses | One miss | Fully compliant |
Run this rubric consistently and your average score across test inputs will tell you when a prompt is ready to ship and when it still needs another revision pass.
Final checklist to ship better prompts
Every prompt in this openai prompt engineering guide comes down to the same core disciplines: clear roles, specific instructions, concrete examples, and consistent testing. Before you run any prompt in production, use this checklist to confirm you haven't skipped a step that will cost you quality at scale.
- Role defined in the system prompt with specific expertise
- Task stated as a positive, direct command
- Format block specifies word count, structure, or field names
- At least one example included for complex or creative outputs
- Boundaries listed as explicit prohibitions, not soft preferences
- Model and temperature selected to match the task complexity
- Prompt tested against five varied inputs before batch use
- Outputs scored against a fixed rubric before shipping
If your content workflow involves video, image, or audio generation alongside text, generate marketing assets with Starpop to put these prompting practices to work across every format you produce.
